Four months ago, we shipped an ITCH parser that hit 107 million messages per second. We wrote about zero-copy design, SIMD optimizations, and lock-free concurrency. The numbers were impressive.
Then it crashed in production.
Not on our benchmarks. Not on our test data. On a real multi-day NASDAQ feed, three months after launch, consuming all available RAM before dying halfway through a trader's backtest.
This is what happened next - the optimizations that prevented 3am pages, the fixes that made the difference between a benchmark and a tool you can actually deploy.
The $10GB Footgun
The crash wasn't a memory leak. It was architectural.
Our parallel parser split large files into chunks for multi-threaded processing. Simple idea: 10GB file, 100MB chunks, send each to a worker thread. Fast and completely broken.
ITCH messages have variable length. Add Order: 50 bytes. Executed Order: 35 bytes. System Event: 12 bytes. They don't align to nice boundaries.
Split at arbitrary byte offsets and you're cutting messages in half. First chunk ends with garbage. Second chunk starts with garbage. Traditional solution: buffer the partial message, wait for the next chunk, reassemble.
At scale, with hundreds of chunks and multiple workers, those partial messages pile up. Memory consumption grows linearly with file size. Eventually: OOM.
We needed a different approach entirely.
Boundary-Aware Chunking
Instead of arbitrary byte boundaries, we now scan the file once and build a map of every message boundary. When splitting into chunks, binary search finds the nearest clean boundary to our target size.
fn build_message_boundaries(data: &[u8]) -> Vec<usize> { let mut boundaries = Vec::with_capacity(data.len() / 32); let mut offset = 0; while offset + 2 <= data.len() { let len = u16::from_be_bytes([data[offset], data[offset + 1]]) as usize; let next = offset + 2 + len; if next > data.len() { break; } boundaries.push(next); offset = next; } boundaries}No split messages. No buffering. No memory explosion. Parallel processing now works reliably on arbitrary file sizes with zero coordination overhead.
Smarter Prefetching
While fixing the chunking bug, we noticed our SIMD prefetching was leaving performance on the table.
We were prefetching one message ahead. By the time we finished processing the current message, the prefetched data had been evicted from L1 cache. We choose the prefetch distance empirically per SIMD width: on AVX2, prefetching 2 messages ahead consistently hides L1 latency without eviction, while AVX-512 benefits from 3 due to higher per-cycle decode throughput. The distance is fixed at startup based on detected CPU features.
We also stopped checking CPU capabilities thousands of times per second. One check at startup, cached result. At 200M+ msg/s, saving 10ns per message saves two full seconds per million messages.
Adaptive Batching
Fixed batch sizes work well for average conditions and poorly for everything else.
Pre-market is quiet - fixed batching means waiting for thousands of messages to accumulate. Added latency. During news spikes, small batches waste time on coordination overhead.
We built adaptive batching that monitors throughput over a sliding window and adjusts batch size in real-time. During quiet periods, batches shrink to minimize latency. During market surges, they grow to maximize throughput. The system computes variance and coefficient of variation - when throughput stabilizes, it reduces adjustments. When conditions change, it adapts aggressively.
Result: same parser handles pre-market quiet and peak trading volume without manual tuning.
Work Stealing
Parallel processing is only as fast as your slowest worker.
Fixed work assignment meant one slow worker (cache miss, complex messages) left other workers idle. We implemented lock-free work stealing using Crossbeam. Workers push to local queues without locks. When done, they steal from others using atomic CAS operations.
Parallel efficiency improved from ~70% to >90% on 16-core systems. Same data, 30% less time, identical hardware.
Validation Without Compromise
We added comprehensive validation without sacrificing throughput:
- Message type validation
- Timestamp bounds (max 86.4T nanoseconds since midnight)
- Size validation preventing buffer overruns
- UTF-8 verification for text fields
- Integer overflow protection in offset calculations
Two modes: Strict stops on any validation failure (development). Lenient logs failures and continues (production).
Invalid messages don't crash the parser. They get flagged, logged, skipped. Your backtest keeps running.
Production Hardening
The changes nobody demos but everyone needs:
16GB max mmap size. Prevents OOM on corrupted files claiming terabyte sizes.
Zero-byte files return clean errors instead of undefined behavior.
try_reserve instead of direct allocation. Low memory gives handleable errors, not panics.
Parallel parser waits for workers to finish before cleanup. No undefined behavior on forced drops.
Consumer threads know whether producers finished or more data is coming. No infinite waits.
These aren't demo features. They're the difference between clean test data and surviving production.
Real-World Impact
Weekly backtests on 3 years of NASDAQ data. 18 hours → 4 hours. One backtest per weekend → multiple strategy variants per day.
Live parser crashed every few weeks under heavy load. Zero crashes in months after boundary alignment fix. Boring reliability. Exactly what matters.
Processing pipeline was customer delivery bottleneck. 85% faster processing. Market close → customer delivery dropped from next morning to within one hour. Infrastructure as competitive advantage.
Speed Plus Reliability
The original parser hit 107M msg/s with a critical bug that crashed on real files.
Current parser handles arbitrary file sizes, prevents OOM crashes, aligns chunks properly, adapts batch sizes dynamically, steals work for load balancing, validates everything, and provides detailed diagnostics.
And it's significantly faster. Benchmarked on AWS m7i-flex.large (Intel Xeon Platinum 8488C, AVX-512):
- SIMD validation: 236+ million msg/s
- Zero-copy parsing: 200+ million msg/s
- SIMD scanning: 140+ million msg/s
- Adaptive batching: 30+ million msg/s with dynamic optimization
- Work-stealing parallel: 25+ million msg/s with near-linear scaling
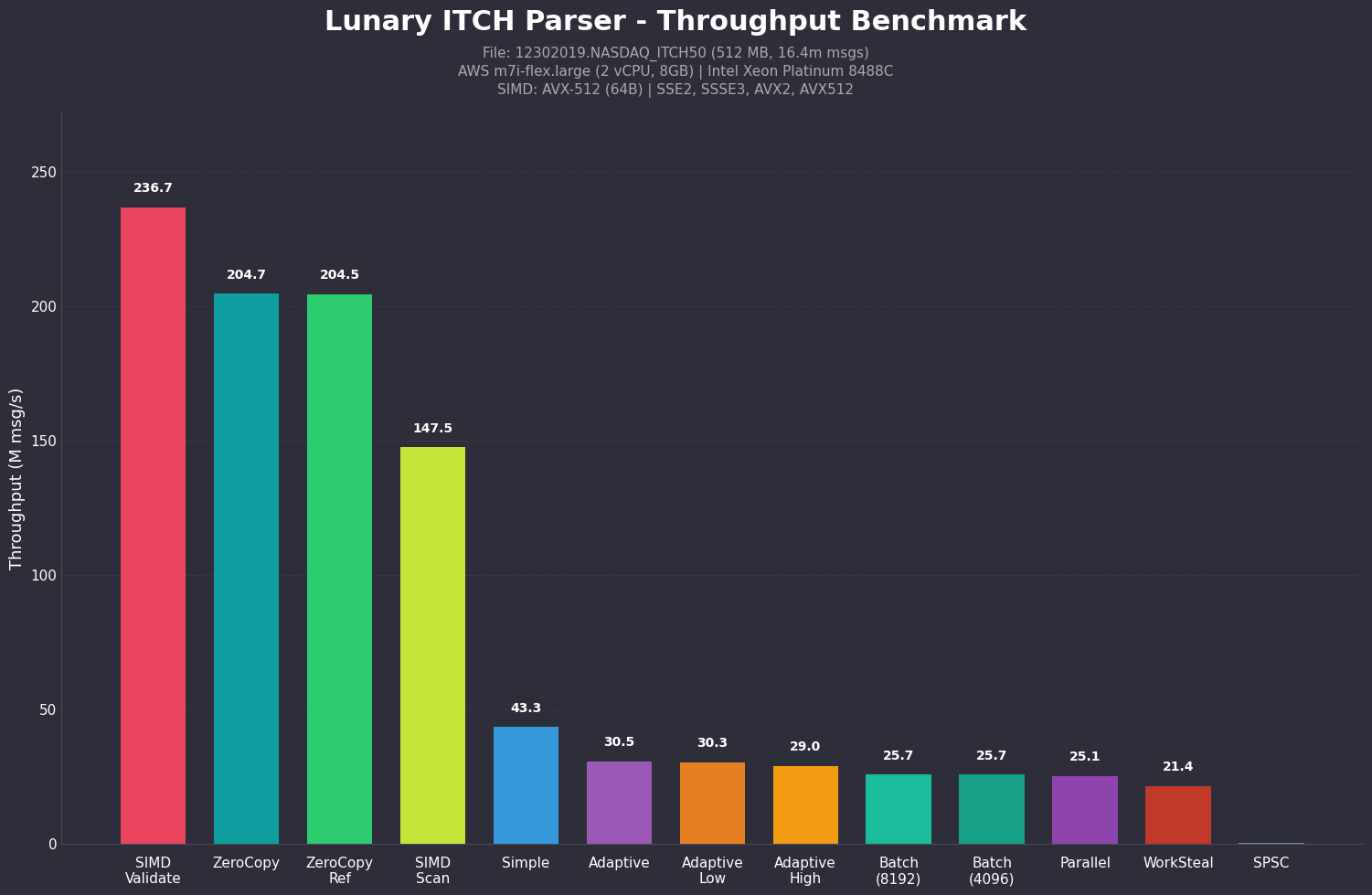
Performance comparison across different parsing strategies and optimizations.
The real improvement isn't just speed - it's that it works. On production data. Under load. For months.
What's Next
We're working on better NUMA awareness for multi-socket systems, incremental parsing for streaming feeds, and more comprehensive validation with detailed diagnostics.
Core lesson from the past year: raw speed is necessary but not sufficient. Production systems need reliability, predictability, and observability as much as throughput.
Lunary is open source. Code on GitHub. Benchmarks reproducible. Numbers real.
If you're processing NASDAQ market data at scale, if parsing is your bottleneck, if you need something that works in production and not just on benchmarks, try it.
We built this to solve a real problem. It does.